Why is sample size important when doing AB testing?
When running AB tests or before starting one, often you will get the question:
“How many observations/users do we need before we can finish the test and make a decision?"
This question is obviously very important from the business perspective, but it is also important from the statistical perspective. In this article we will explain why.
Hypothesis testing
When you want to figure out which version of your game has higher retention rate or which ad has higher conversion rate you need to collect some data and then do some statistics. There are two general ways of thinking in statistics: frequentist and Bayesian. Here we will discuss hypothesis testing in frequentist setting.
When doing hypothesis testing you would assume that conversion rate is the same and call this the null hypothesis (H0). The opposite of the null hypothesis is that conversion rates are different which we call the alternative hypothesis (H1). The question is should we reject the null hypothesis or not, based on the observed data.
After doing the test there are 4 things that can happen:
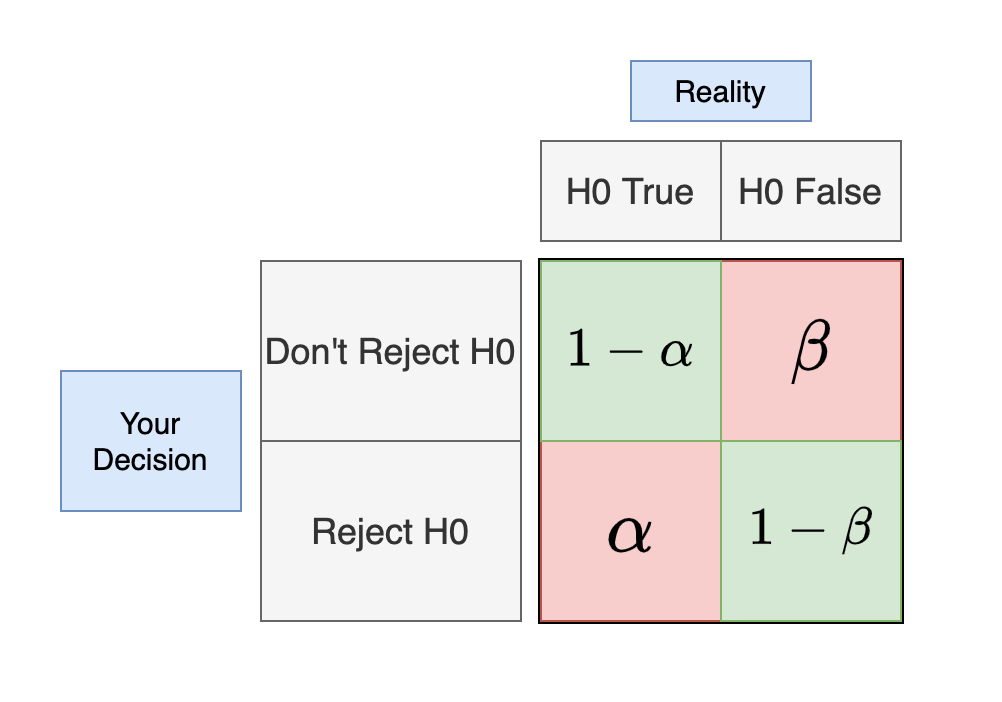
Different types of errors
The red squares are where you don’t want to end up. We call them errors and there are two types:
- Type I error ($\alpha$): Reject H0 when it is True
- Type II error ($\beta$): Not rejecting H0 when it is False
Type I error is when you say your ads A and B have different conversion rates, when they don’t. Type II error is when we fail to see that conversion rates between two ads are different, when in reality they are.
Numbers, (or more precisely letters :)) in the squares represent these errors and their probabilities. If we set $\alpha = 0.05$, that means that we will make type I error in at most 5% of our tests. If we set $\beta = 0.05$ that means we will make type II error in at most 5% of our tests.
In practice
Usually when testing one would say: “I want statistical significance to be 5%”. That means that we want Type I error ($\alpha$) to happen in less then 5% of our tests. In other words, we want to make mistake of choosing the variation when there is no difference in less then 5% of the time. That is great and we should want that.
But often, that is the end. We don’t say anything about type II error. To see why this is important, let’s do a thought experiment. Say we did 100 AB tests of conversion rates for our ads. In each AB test our new ad had higher conversion rate. But we only collected such amount of data that our type II error is $\beta = 0.4$ (40%). That means that in 60 tests we will see that ad B is better and use it. In 40 tests we won’t see statistically significant difference between the ads and we won’t use those ads. That is a lot of missed opportunities. If type II error is 50% or even 70%, that is even worse. If you don’t calculate type II error ($\beta$) then you have no idea how often you miss out on those opportunities…
Solution
So can we just say we want each of those errors to be happening at most 5% of the time. Yes we can! But… we need to be ready to collect a lot of data then. A lot. That often won’t be possible in business. So, we need to find a good balance.
In statistics, often you will hear about the statistical power of the test. That power is actually $1 - \beta$, the probability of rejecting H0 when it is false. So, instead of speaking we want type II error to be 5%, we can say we want statistical power to be 95%. We want to detect 95% of our improvements where there is one. We want to see and use 95% of our opportunities.
Usually, the value used for the statistical significance $\alpha$ is 5%, but depending on the application you can choose 3%, 1% or go up to 10%. You can choose 2.3948% if you want.
Usual value for the statistical power $1-\beta$ is 80%. Because increasing power more will require much more data. If you can collect enough data you can go up to 90% or even 95%.
It is important to calculate the power of your test. You don’t want to be wasting your time running tests that have low power, say 50% or even less.
How to calculate sample size?
In order to calculate sample size you can use the online calculator that I created for such purpose. The link is here:
It takes some time to load because server is running the app on request only, not to waste resources all the time.
For details about using the calculator and some examples of sample sizes check out the post here.